

Μια συνοπτική σύγκριση
Αν έχετε ασχοληθεί με την ανάπτυξη εφαρμογών/προγραμμάτων που επικοινωνούν με άλλα υπάρχοντα συστήματα (APIs/Services), τότε πολύ πιθανό να εφαρμόσατε κάποιας μορφής ETL (πιο σύνηθες από οτι μια ELT) διαδικασία – είτε το συνειδητοποιήσατε, είτε όχι. Στην προσπάθεια σας να συλλέξετε τα δεδομένα από κάποια εξωτερική υπηρεσία και να τα τροποποιήσετε πριν τα αποθηκεύσετε σε μια τυπική βάση δεδομένων, γνωρίσατε μια από τις θεμελιώδεις διαδικασίες στο χώρο των δεδομένων.
Στον κόσμο του Data Engineering και των παρεμφερών κατευθύνσεων, οι έννοιες του ETL (Extract – Transform – Load ~ Εξαγωγή – Μετασχηματισμός – Φόρτωση) και του ELT (Extract – Load – Transform ~ Εξαγωγή – Φόρτωση – Μετασχηματισμός) παίζουν καθοριστικό ρόλο. Αν και ο αναγραμματισμός φαίνεται μικρός, οι διαφορές ανάμεσα στις δύο “φιλοσοφίες” είναι σημαντικές, ξεκινώντας από τις βασικές ενέργειες και περιπτώσεις χρήσης και καταλήγουν ακόμα και στο κόστος που μπορούν να έχουν ή την επίδραση στην απόδοση του pipeline που θέλετε να σχεδιάσετε.
Παράδειγμα: Αναλύοντας την επισκεψιμότητα ενός website
Θα ήταν πιο εύκολο να ορίσουμε και να ξεχωρίσουμε τα προ-αναφερθέντα χρησιμοποιώντας ένα όσο-το-δυνατό πραγματικό παράδειγμα. Συνεπώς, για τις ανάγκες του άρθρου, μπορούμε να θεωρήσουμε ότι βρισκόμαστε σε ρόλο αναλυτή και καλούμαστε να εξάγουμε συμπεράσματα για την κίνηση/επισκεψιμότητα ενός website.
Έτσι, με πιο απλά λόγια, εάν επιλέγαμε ένα ένα ETL (pipeline) για να κάνει τη δουλειά τότε αυτό θα:
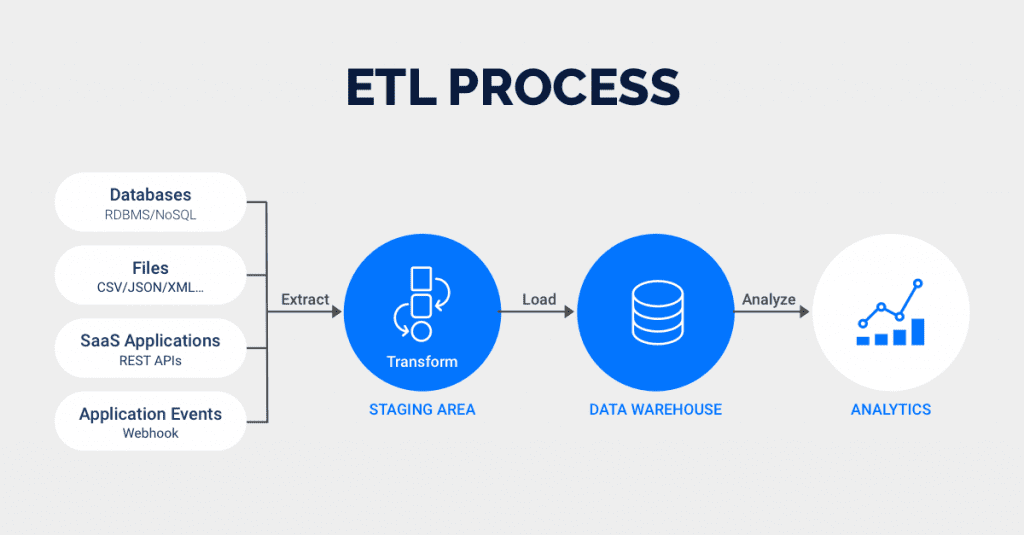
- Εξάγει (Extract) διάφορα δεδομένα από τα logs του web server (π.χ. Nginix) ή/και διάφορα event data από το Google Analytics ή οποιοδήποτε άλλο (π.χ. custom made) σύστημα που παρακολουθεί την κίνηση.
- Σε επίπεδο εφαρμογής μετασχηματίζει (Transform) τα δεδομένα με κάποια κριτήρια πριν την αποθήκευση τους. Λόγου χάρη, μπορεί να καθαρίσει τα δεδομένα που παράγονται από τις επισκέψεις των bots, να υπολογίσει εκ των προτέρων τη διάρκεια παραμονής κάποιου στο website ή να κάνει διάφορες ομαδοποίησεις που καλύπτουν τις ανάγκες του πελάτη.
- Φορτώνει (Load) τα δεδομένα σε μια τυπική βάση δεδομένων ή κάποιο Data Lake (Τα δεδομένα αυτά δεν χρειάζονται περαιτέρω επεξεργασία).
Από την άλλη ένα ELT (pipeline):
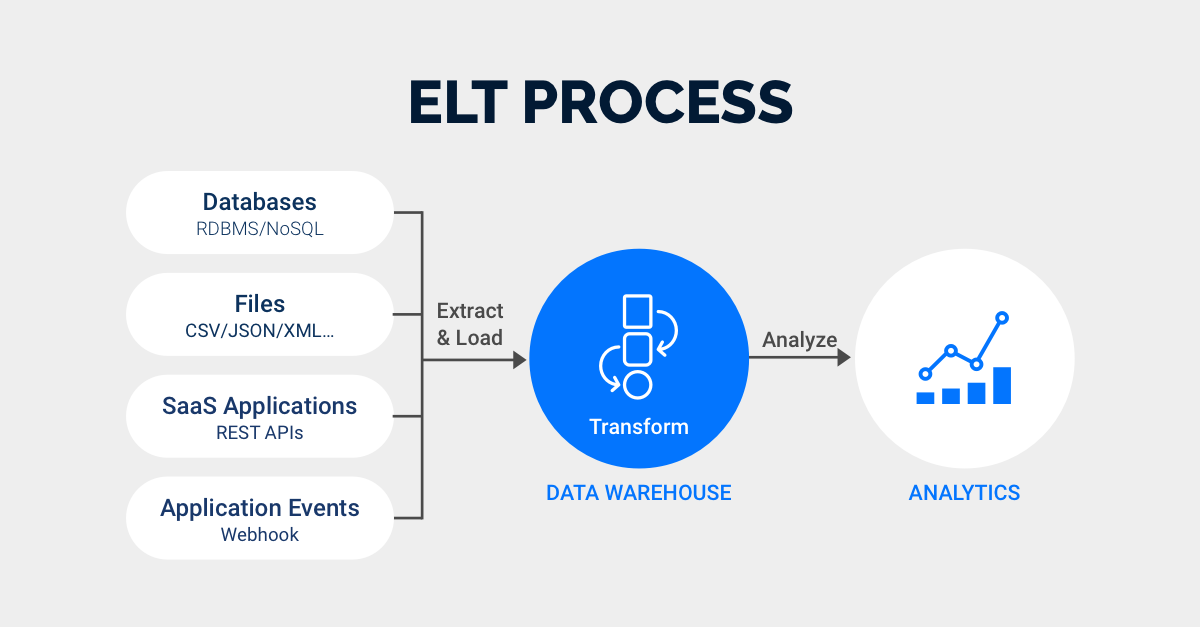
- Εξάγει (Extract) δεδομένα από τις πηγές.
- Τα δεδομένα φορτώνονται (Load) σε κάποιο Data Warehouse (DW), π.χ. BigQuery, στην αρχική (raw) μορφή τους, όπως π.χ. μια δομή JSON.
- Ο μετασχηματισμός (Transform) πλέον γίνεται σε επίπεδο DW, με χρήση views, window functions και άλλων SQL εργαλείων.
Ποια μέθοδο να διαλέξω; Και γιατί;
Γνωρίζοντας πλέον πως ενεργεί ως επί τω πλείστον κάθε ένα από αυτά, δημιουργείται εύλογα η απορία: “πότε, που, και γιατί τα χρησιμοποιώ”; Φυσικά κάτι τέτοιο δεν γίνεται τυχαία και εξαρτάται κυρίως από τη διαθέσιμη υποδομή, τον όγκο των δεδομένων, τις δυνατότητες του μέσου αποθηκεύσης (βάση ή αποθήκη δεδομένων) και φυσικά τις ανάγκες του project/πελάτη.
Πιο αναλυτικά, και αφού η ειδοποιός διαφορά ανάμεσα τους είναι στην πράξη που γίνεται ο μετασχηματισμός των δεδομένων, θα μπορούσαμε να πούμε ότι συνιστάται αυτός να γίνει πριν το ανέβασμα στο σημείο αποθήκευσης όταν υπάρχει ανάγκη για ακριβή καθαρισμό, έλεγχο ή κανονικοποίηση των δεδομένων πριν αυτά φορτωθούν. Ένα τέτοιο παράδειγμα θα μπορούσε να είναι ο χειρισμός ευαίσθητων δεδομένων. Τέτοια στοιχεία είναι πιο ασφαλές να απομακρύνονται ή να αγνοούνται ήδη από το στάδιο της συλλογής ώστε να αποφευχθεί η αθέμιτη χρήση τους. Δεδομένου, επίσης, ότι κάτι τέτοιο γίνεται σε τυπικές σχεσιακές βάσεις δεδομένων, αυτόματα σημαίνει ότι και οι πόροι/δυνατότητες της επεξεργασίας είναι περιορισμένοι. Έτσι, σε ένα σενάριο όπου ο όγκος των δεδομένων είναι υπερ-αρκετός είναι προτιμότερο να “μαγειρέψουμε” τα δεδομένα μετά την αποθήκευση, γλιτώντας επίσης και το κόστος που πρέπει να χρειαστεί το “staging area” – το ενδιάμεσο-προσωρινό επίπεδο αποθηκεύσης.
Οι σύγχρονες cloud πλατφόρμες, για παράδειγμα το Google Cloud Platform, προσφέρουν λύσεις όπως το BigQuery που πραγματοποιούν ταχύτατα πράξεις που σε application-level θα έπαιρναν περισσότερο χρόνο. Είναι επίσης σημαντικό να διατηρούμε τα δεδομένα στην αρχική (raw) μορφή τους, ώστε ανά πάσα στιγμή να μπορούμε να επιστρέψουμε σε αυτά και να τα επεξεργαστούμε εκ νέου με διαφορετικό τρόπο ή διαφορετικό σκοπό. Ο παραδοσιακός τρόπος ETL δεν υποστηρίζει εύκολα επισκέψεις σε παλαιότερα πακέτα δεδομένων.
Επίλογος
Το Schema Evolution και η ευελιξία ή όχι που προσφέρει κάθε μέθοδος είναι επίσης σημαντική. Κάθε αλλαγή στη δομή των δεδομένων που λαμβάνουμε συνεπάγεται και αλλαγή του κώδικα που δέχεται αυτά τα δεδομένα (και δεν τα αποστέλλει απλώς στο μέσο αποθήκευσης). Εάν αποθηκεύουμε κατευθείαν την JSON μορφή των δεδομένων τότε ο loader δεν χρειάζεται να αλλάζει με κάθε ενημέρωση στην δομή απάντησης από τα συνεργαζόμενα APIs.
Όπως καταλαβαίνατε δεν πρόκειται για άσπρο και μαύρο. Αν και μπορούμε να βάλουμε ταμπέλες “μοντέρνας και παλαιότερης γενιάς” στην πράξη χρησιμοποιούμε ETL ή ELT διαδικασίες ανάλογα τον σκοπό μας και με όποια εργαλεία έχουμε στη διάθεση μας.
